
SQL Server provides a variety of ways to tune XML so that it provides consistent performance, consumes less space, all while ensuring efficient access to critical data.
At its core, the metadata-styled XML format runs counter to the data that SQL Server is optimized to manage. Therefore, additional features were added to SQL Server over time that allowed for XML data to be indexed and compressed.
While these features are critical for managing XML data as it becomes large, it is important to remember what XML is intended for and why it is (loosely) structured as it is. Many data professionals have used shortcuts when XML was small, such as storing and analyzing it in string format, only to be forced to reckon with performance challenges when scanning large strings become agonizingly slow.
Indexing XML for Faster Searches
If there is a need to query a table and filter on an XML column, then XML indexes can be used to support these queries. Adding XML indexes to a table can help ensure that full table scans are not required to retrieve rows based on an XML filter.
It is important to note that indexing XML columns is not as efficient as storing values in columns and indexing them with standard non-clustered indexes. If an XML column is expected to be searched very often, updated very often, and otherwise be pivotal in OLTP data scenarios, there is value in storing key filter column values from the XML document in separate columns, indexing them, and querying those columns instead. This is only scalable when the number of columns to normalize and query is small, but it is an efficient way to sidestep the need for heavy XML manipulation, which can be computationally expensive.
XML Indexes are fundamentally different than standard clustered and non-clustered indexes and require some additional knowledge to effectively use.
Note: The code in this article assumes you have created the objects in the first article in this two part series: Effective Strategies for Storing and Parsing XML in SQL Server if you wish to execute the code in this article.
Primary and Secondary XML Indexes
XML columns may be indexes with primary and secondary XML indexes, which are similar in usage to clustered and non-clustered indexes. There are some rules that apply to XML indexes that are fundamental to their usage:
- An XML column may only have one primary XML index.
- A primary XML index may not be created on a table unless it already has a clustered rowstore index.
- A secondary XML index cannot be created without a primary XML index.
- Dropping a primary XML index will automatically drop all secondary XML indexes without a warning or informational message.
Consider the following query:
|
1 2 3 4 5 6 |
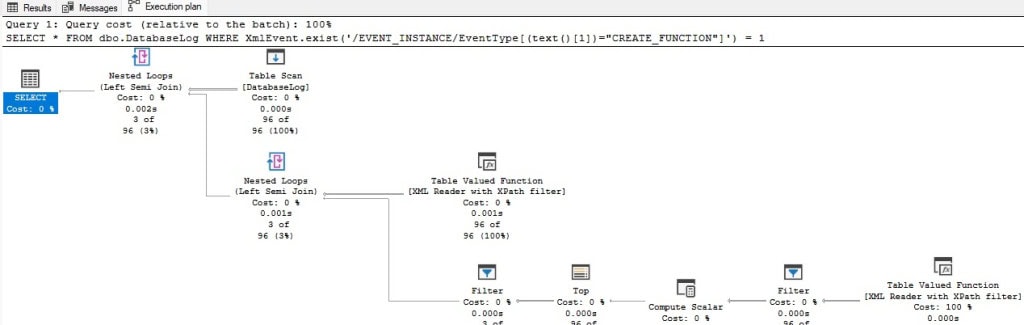
SELECT DatabaseLogID, PostTime, [Object] FROM dbo.DatabaseLog WHERE XmlEvent.exist('/EVENT_INSTANCE/EventType[(text()[1])="CREATE_FUNCTION"]') = 1 |
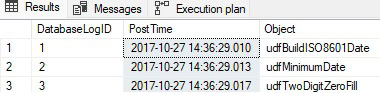
This is filtering for any rows in dbo.DatabaseLog where the XmlEvent contains an EventType of CREATE_FUNCTION. Without any indexing to support this query, the entire table will need to be scanned to determine which rows satisfy the filter. In this case, there are three rows returned:
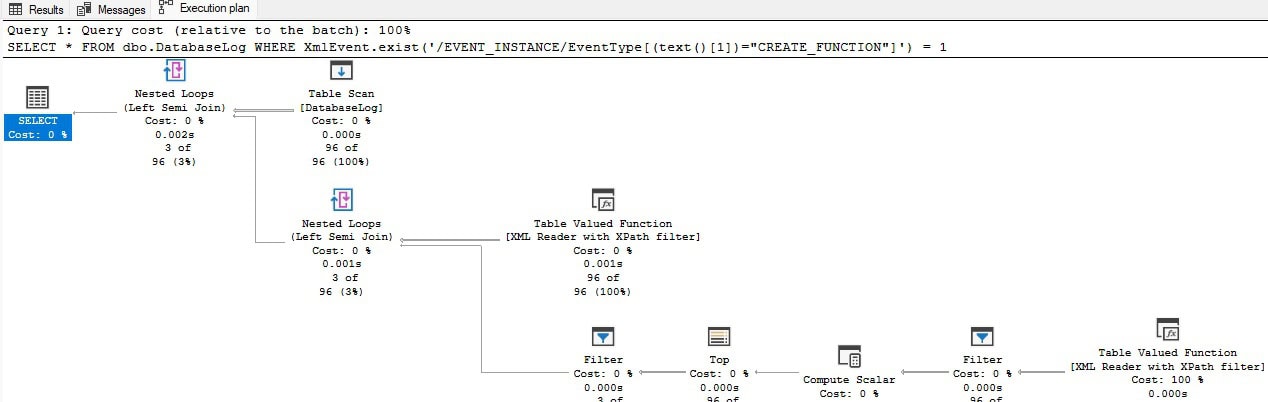
Despite only returning three rows, the entire table needs to be scanned in its entirety to get these results, along with some serious XML parsing:
If this were a critically important query, then adding an XML index could greatly improve performance. The following T-SQL creates the primary XML index for this column:
|
1 2 |
CREATE PRIMARY XML INDEX IX_DatabaseLog_XmlEvent ON dbo.DatabaseLog (XmlEvent); |
The result harkens back to one of the rules listed earlier:
Msg 6332, Level 16, State 201, Line 396
Table 'dbo.DatabaseLog' needs to have a clustered primary key with less than 32 columns in it in order to create a primary XML index on it.
It turns out that this table has a non-clustered primary key defined on it. The following query replaces it with a clustered primary key:
|
1 2 3 4 5 6 |
ALTER TABLE dbo.DatabaseLog DROP CONSTRAINT PK_DatabaseLog_DatabaseLogID; ALTER TABLE dbo.DatabaseLog ADD CONSTRAINT PK_DatabaseLog_DatabaseLogID PRIMARY KEY CLUSTERED (DatabaseLogID); |
Now executing the XML index creation statement above works as expected. The primary XML index behaves like a clustered index and indexes all paths, tags, and nodes. While this will cover many types of XML queries, it is also a large index to scan. Note that the execution plan for the query that was run earlier has changed:
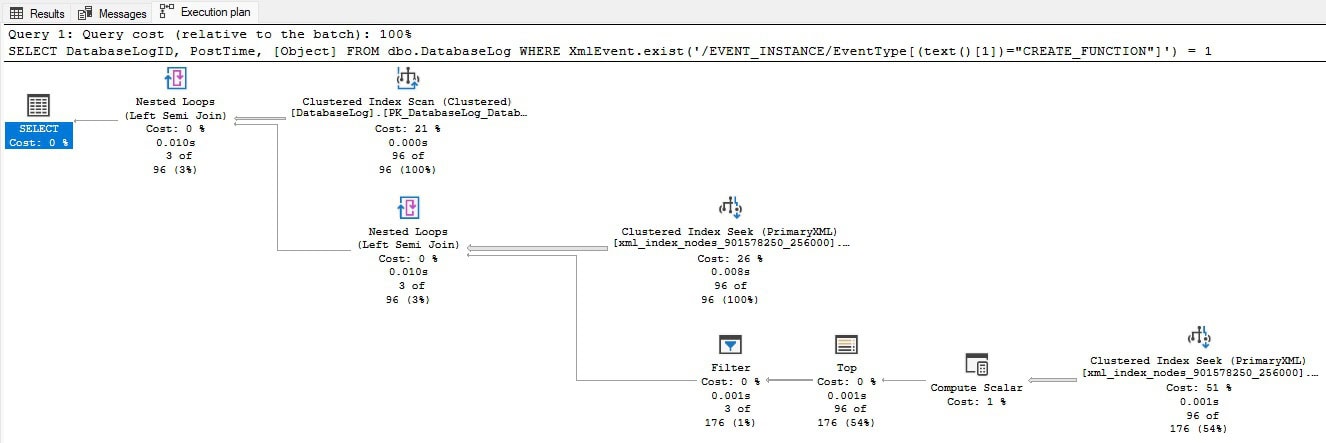
While the execution plan is still complex and involves a clustered index scan, the query completes faster as the amount of IO to return the requested results is much lower than it was previously.
If this were a very large table and the performance of the XML query was crucial to an application’s success, then a secondary XML index could be beneficial. The secondary XML index is defined on PATH, VALUE, or PROPERTY and indexes only the parts of the XML document that are of that type. This generates a smaller index that is faster to seek than the primary XML index. The cost is the same as it is for all indexes in that there is an additional index that requires updating whenever rows are inserted, deleted, or the XML column is updated.
The following index could provide added support for the query that has been tested here:
|
1 2 3 4 |
CREATE XML INDEX IX_DatabaseLog_XmlEvent_Secondary ON dbo.DatabaseLog (XmlEvent) USING XML INDEX IX_DatabaseLog_XmlEvent FOR PATH; |
Once added, the execution plan once again changes for the test query:
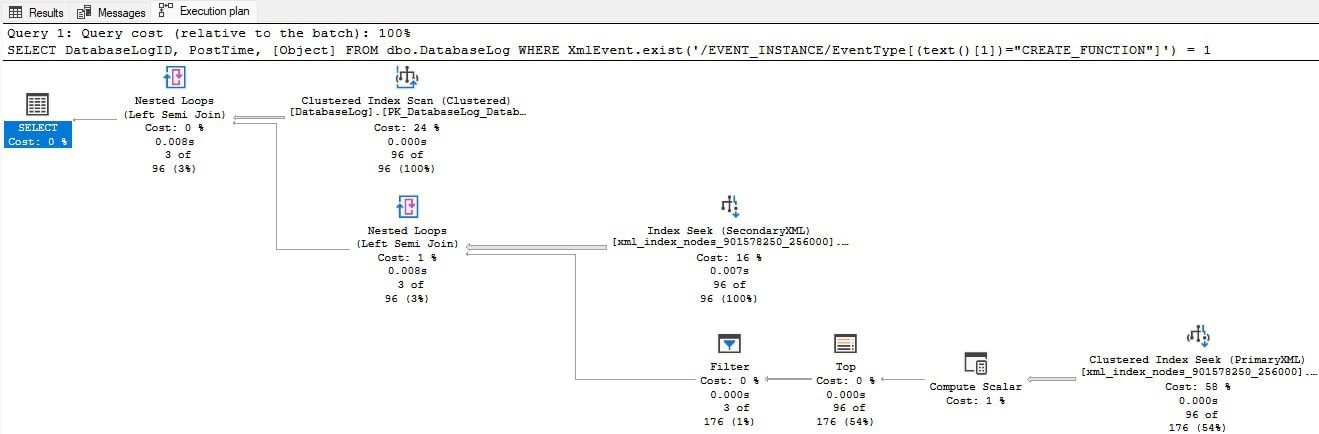
While the execution plan is still complex, the query is speeding up with each iteration of indexing improvement.
Selective XML Indexes
For scenarios where a very specific query is used often and the details of how it is used do not change significantly, then selective XML indexes can provide a more significant performance improvement while also boasting a smaller index structure.
For example, the query tested previously relied on an existence check against EventType for one specific value. If this is a critical query pattern, then the following selective XML index can help:
|
1 2 3 |
CREATE SELECTIVE XML INDEX IX_DatabaseLog_XmlEvent_Selective ON dbo.DatabaseLog (XmlEvent) FOR (EventType = '/EVENT_INSTANCE/EventType'); |
This syntax specifies exactly what XML element is to be indexed. This makes the index far narrower than any others demonstrated so far. Primary XML indexes need to handle the entirety of an XML document whereas secondary indexes choose an entire category of XML details to include. In contrast, the selective index will be tiny in comparison as it can be targeted to cover a specific query or set of queries.
The execution plan shows the use of the selective index:
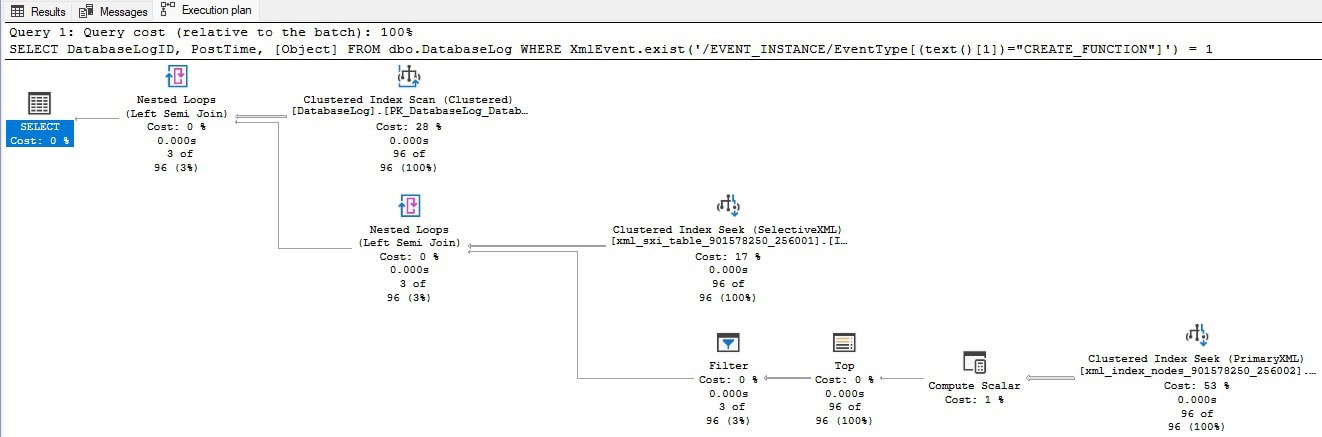
This is by far the most efficient way to query based on the XML filter criteria provided.
While selective XML indexes are not helpful for query patterns that change and evolve often, they address individual queries effectively where the key columns are not expected to change.
Performance
XML indexing can greatly improve the performance of frequent searches against XML columns in SQL Server. Despite this potential benefit, XML indexes are large, complex, and computationally expensive to update and maintain. It is important to weigh the benefit of each approach for querying a table before implementing one.
If an XML column is very rarely filtered on, then maybe those occasional index scans are tolerable. Alternatively, if a single element within an XML document is queried very frequently, then normalizing that element into a column within the table and indexing it could be a far more efficient way to improve performance.
This is a balancing act where less complexity will generally be beneficial. If it is possible to solve a problem without XML, then doing so will likely consume less space and provide better performance. If XML is required and crucial to an application’s function, then adding primary and secondary XML indexes can be key solutions.
Compressing XML
Starting in SQL Server 2022, XML columns can be compressed. This includes off-row data for both tables and indexes. Like compressing other data types, this compression may be selected on a partition-by-partition basis. Therefore, if a table is partitioned, some partitions may be compressed while others remain uncompressed.
Compressing XML columns means that they will not only consume less space at-rest but will continue to use less space when their pages are read into memory. Data pages are not uncompressed until needed at runtime. If backups are not natively compressed, then XML compression will also reduce backup size.
XML compression fundamentally changes how XML-typed columns are stored, using a compressed binary format. While the data is stored differently, all the methods for accessing compressed XML data remain the same. XML columns may be compressed without the need for changes to any applications that use the data. A table may have standard row or page compression in addition to XML compression or a combination of both.
The following example creates a new table and applies compression automatically to XML columns:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE dbo.XMLCompressionTest ( id INT NOT NULL CONSTRAINT PK_XMLCompressionTest PRIMARY KEY CLUSTERED, FirstName VARCHAR(250) NOT NULL, LastName VARCHAR(250) NOT NULL, UserMetadata XML) WITH (XML_COMPRESSION = ON); |
Note that this compression will not be visible in the table metadata. For example, checking the properties in SQL Server Management Studio for this table will show no compression:
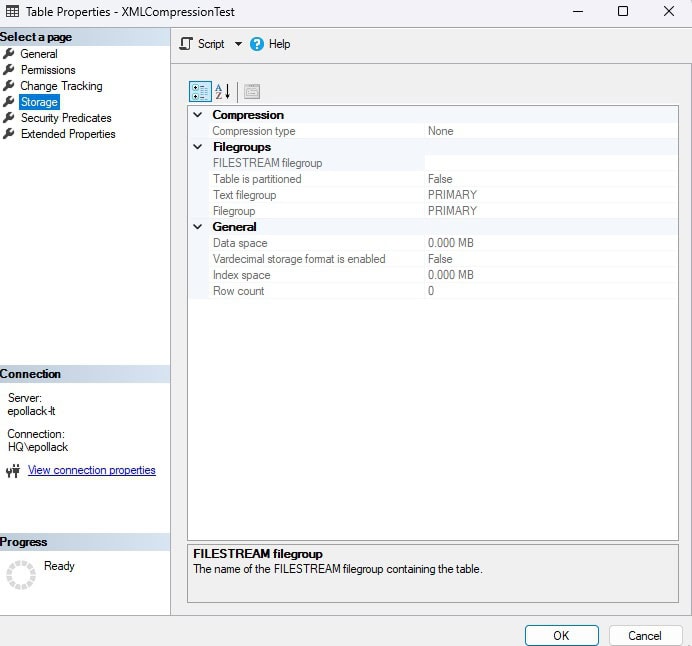
Since XML compression and standard row and page compression are separate features, they are reported separately in SQL Server. XML table compression is reported in sys.partitions for each partition, and can be checked via a query similar to this:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT tables.[name] AS TableName, indexes.[name] AS IndexName, partitions.partition_number, partitions.xml_compression FROM sys.indexes INNER JOIN sys.tables ON tables.object_id = indexes.object_id INNER JOIN sys.partitions ON partitions.object_id = tables.object_id AND partitions.index_id = indexes.index_id WHERE tables.name = 'XMLCompressionTest' |
The results show the single partition for this table and its compression setting:

If this table were partitioned, then there would be a row per partition and the XML compression setting reported individually for each partition.
Note that like row and page compression, XML compression is managed on a partition-by-partition basis. If a table is partitioned and there are different compression settings for different partitions, then any rebuild operations must honor those settings, or they will be lost.
Compressing XML indexes requires enabling compression as part of their creation, just like with standard row or page compression. A table with XML compression will not impart compression onto subsequent XML indexes that are created unless compression is explicitly enabled for them. The following script creates a primary XML index on UserMetadata, explicitly enabling XML compression on the index:
|
1 2 3 |
CREATE PRIMARY XML INDEX IX_XMLCompressionTest_UserMetadata ON dbo.XMLCompressionTest (UserMetadata) WITH (XML_COMPRESSION = ON); |
If there is no plan to modify XML data selectively, then consider testing and implementing XML compression on tables that have XML columns. The space savings can be significant. If there is a need to frequently update XML columns, then exercise caution with compression and only implement if testing shows that the storage/memory gains are worth the penalty paid when the data is updated.
What About Using Strings for XML?
A common tactic for managing XML data has been intentionally omitted from this series. A brute-force approach for working with XML data is to convert it to VARCHAR/NVARCHAR text and then use string manipulation functions to select or update its contents accordingly.
While this approach works, it is inefficient and eliminates the performance optimizations and XML functionality offered by SQL Server. A relational database engine is not a text-searching tool and will generally be inefficient in this role (certainly compared to engines built for semi-structured data). If text-based search is required by an application, then do not use XML or another markup language. Instead use Full-Text Indexing or another service that is designed explicitly to search text data efficiently.
For one-off scripts or other scenarios where performance simply doesn’t matter, and where a brute-force approach is seen as OK, then this may an acceptable way to solve a problem quickly. Once a process is to be repeated many times or added into permanent code, then the best solution to an XML problem is to use an XML solution.
XML often finds its way into code as a fast or brute-force way to resolve a problem quickly by introducing semi-structured data into a structured data application, but should only be used when it is the optimal tool for the job. XML is an excellent tool for transporting data between applications or services as it is an open standard and highly portable. It should not be used as a replacement for:
STRING_SPLITSTRING_AGG- Full-text indexing, Elastic search, or other text-based applications/engines
- Relational data
- Data warehouse data
- Data lake data
This is especially important when first architecting a data solution. Choose the right tool for the job the first time. If there is uncertainty as to what the ideal tool is, work with other developers or product owners to fully understand the use-cases for this data. Doing so will reduce the opportunity for technical debt to creep into an application and waste precious time and resources. As a bonus, your colleagues will not hate you  .
.
Conclusion
As mentioned in part 1 of the series, XML is a commonly used tool for storing and moving data between applications. It is an easy-to-use open standard that has an extensive amount of functionality built-in for querying and updating it. SQL Server provides many ways to read and write XML data, as well as optimizations to improve search speeds and reduce its storage footprint.
Like many tools available to us, there is a balancing act between functionality, performance, and familiarity that we face whenever deciding where to store our data. Managing that challenge effectively will ensure that features such as XML are used optimally and when most appropriate.
Using specialized XML indexes, we can get decent performance when dealing with XML data, but it should only be used when the structure of the data cannot be known at design time, because using rowstore and columnstore indexes will provide far greater performance.


