
When an application searches for specific text data, you can generally rely on it to get the search term right. For example, if it needs to find ‘sausages’, you won’t expect to receive a search on ‘sossyjez’ , however, When people search your website or application, they have grown to expect it.
In this article, I’ll be explaining some of the strategies that you can adopt to make the searches that are made by users more satisfactory for them. Although they are well-tried in the industry, It is rare to hear of them being used in SQL.
General principles
When you create your application, you will need to have an ‘inversion table’ that lists all the words that are legitimately ‘searchable’. This technique is described here. If, for example you are selling widgets, the inversion table would contain a list of widgets, and the widget spares, repairs, advice, instructions and so on. At this stage, we’ll stick to a single language site, but if your site is multi-language, then the structure of the related tables is rather different.
This word list will be referenced, by a foreign key constraint, from a large narrow table that records where the various entities that are associated with the word are stored, so that relevant matches, maybe a link, a phrase, a description or an image, can be returned to the user. This second table usually records at least the location of the text and the sequence number of the word in the text, where it occurs. It is the inversion table, containing the list of words, that we’ll focus on in this article.
The task
When users search the site, even if they are using a single language, they will misspell or use national spellings. They will also use dialect words, or specialist words, for the widget, and even then they may get the spelling wrong. They will use argot or even textspeak (‘I H8 U 4 UR HCC’).
In short, your “fuzzy search” algorithm ought to be able to cope with a lot of creative ways to search for the same thing, for example:
- dialect differences – crayfish, crawfish, écrevisse, crawdads, yabbies
- national spelling differences – yoghourt, yogurt and yoghurt
- national word differences – pants and trousers
- multiple valid spellings – encyclopaedia, encyclopedia
- misspellings – definitely often rendered as definitly, definately or defiantly
- mistyping – computer as copmuter or comptuer.
We’ll use three basic techniques to cope with all this: the ‘edit difference’, the hardcoded ‘common misspelling’ lookup, and the sound-alike. Although some of the ways that words become difficult to match are dealt with by the lookup, and the ‘edit difference’ approach is good for interpreting mistyping, in truth, both that and the sound-alike technique work together to catch a wide variety of errors.
The Test-bed
To set this up, we’ll have our inversion table. We’ll also need a function to generate metaphones for when we get to the ‘sound-alike’ techniques
All we need to start is a list of all the common words in the English language. To this we can then add the common mistypings and ‘aliases’(by which I mean dialect words or national differences). The list of common words can be found all over the internet but is here in the SQL of Scrabble and Rapping or the Fireside Fun of Decapitations. Common Mistypings and common misspellings are available in the public domain. Dialect words and national differences are dependent on your location. You’ll also need to load the code for the metaphone function from here
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE TABLE words (word VARCHAR(40) PRIMARY KEY, CanonicalVersion VARCHAR(40), Metaphone VARCHAR(10) NULL, Word_id int IDENTITY UNIQUE ) ALTER TABLE dbo.Words ADD CONSTRAINT FK_canonical FOREIGN KEY (CanonicalVersion) REFERENCES dbo.words(Word) ; GO /* this is just a temporary expedient */ CREATE TABLE #words (word VARCHAR(40) ) /* we unpack the wordlist and put it in a directory on the server hosting our SQL Server instance */ INSERT INTO #words(word) EXECUTE master..xp_cmdshell 'type OurDirectory\wordlist.txt' DELETE FROM #words WHERE word IS NULL insert INTO words (word,Metaphone) SELECT word, dbo.metaphone(word) FROM #words -- now we need an index on the metaphone CREATE INDEX idxMetaphone ON words (metaphone) DROP TABLE #words |
You can then insert your secondary ‘alias’ words like this
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO words(word, Metaphone) SELECT good, dbo.metaphone(good) FROM (VALUES ('across','accross' ), ('aggressive','agressive'), ('aggression','agression'), ('apparently','apparantly'), ('appearance','appearence'), ('argument','arguement'), |
…and so on through to
|
1 2 |
('wherever','whereever'), ('which','wich'))f(good,bad) |
Now, you can select both the standard ‘canonical’ words and the ‘aliases’
|
1 2 |
SELECT COALESCE(words.CanonicalVersion, words.word) FROM dbo.words WHERE words.word = @Searchterm; |
Or you may want to just search the canonical words by excluding the aliases by adding the condition
|
1 |
AND words.CanonicalVersion IS NULL |
Edit Difference
We can use the ‘edit difference’ technique to cope with simple mistyping or misspelling errors.
When you compare words, and need a measure of how alike they are, you generally calculate how many single-character edits, deletions, transpositions, replacements and insertions you would need to make to get from one to the other. It is commonly believed that to search for a word, you need to calculate the number of edits required to change your candidate word to any other word in the inversion table. Well, no. This would take at least thirteen seconds on our word list, with the full Damerau-Levenshtein algorithm.
A much simpler and faster technique is to select just the candidates that are one ‘edit difference’, or Levenshtein Distance, away because you only want candidate matches that are similar.
You just produce all the character strings that are one edit distance away and do an inner join with your table of words to eliminate the vast majority that aren’t legitimate words in your table. This deals with the majority of errors. No fuss at all.
Here is the code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
IF OBJECT_ID (N'dbo.OneEditDifferenceTo') IS NOT NULL DROP FUNCTION dbo.OneEditDifferenceTo GO CREATE FUNCTION dbo.OneEditDifferenceTo(@Word Varchar(40)) /** summary: > Returns all common words that are one edit difference away from the input word. The routine generates all the character strings that are one edit distance away and does an inner join with the table of words. Author: Phil Factor Revision: 1.0 date: 16/02/2017 example: Select * from dbo.OneEditDifferenceTo('osd') Select * from dbo.OneEditDifferenceTo('acheeve') Select * from dbo.OneEditDifferenceTo('erty') returns: > a table containing strings Dependency: WORDS. A table of common words **/ RETURNS @candidates TABLE ( Candidate VARCHAR(40) ) AS -- body of the function BEGIN DECLARE @characters TABLE ([character] CHAR(1) PRIMARY KEY) DECLARE @numbers TABLE (number int PRIMARY KEY) INSERT INTO @characters([character]) SELECT character FROM (VALUES ('a'),('b'),('c'),('d'),('e'),('f'),('g'),('h'),('i'),('j'),('k'),('l'),('m'), ('n'),('o'),('p'),('q'),('r'),('s'),('t'),('u'),('v'),('w'),('x'),('y'),('z'))F(character) INSERT INTO @numbers(number) SELECT number FROM (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12),(13), (14),(15),(16),(17),(18),(19),(20),(21),(22),(23),(24),(25),(26),(27),(28),(29), (30),(31),(32),(33),(34),(35),(36),(37),(38),(39),(40))F(number) INSERT INTO @Candidates(candidate) SELECT DISTINCT word FROM (--deletes SELECT STUFF(@word,number,1,'') FROM @numbers WHERE number <=LEN(@Word) UNION ALL--transposes SELECT STUFF(@word,number,2,SUBSTRING(@word,number+1,1)+SUBSTRING(@word,number,1)) FROM @numbers WHERE number <LEN(@Word) UNION ALL --replaces SELECT DISTINCT STUFF(@word,number,1,character) FROM @numbers CROSS JOIN @characters WHERE number <=LEN(@Word) UNION ALL --inserts SELECT STUFF(@word,number,0,character) FROM @numbers CROSS JOIN @characters WHERE number <=LEN(@Word) UNION ALL --inserts at end of string SELECT @word+character FROM @characters )allcombinations(generatedWord) INNER JOIN dbo.words ON generatedWord=word WHERE words.CanonicalVersion IS null RETURN END GO |
With a test bank of 147 common misspellings, the function failed to come up with the correct version only thirteen times. That is less than a ten percent failure rate. In all, it took 380 ms on a slow test server to find all the one-edit-difference matches for 147 words. That’s roughly 2.6 ms each
This might be all you need for some applications, but we can pick up most of the mis-spellings that the edit-difference search failed to find, such as phonetic misspellings, using sound-alike.
Sound-Alike
For words that are mis-typed phonetically, there is the Metaphone algorithm. There are more advanced and much more complicated versions of this, but I’m using the early public-domain form. I have a SQL Version here. Soundex, which is built-in to SQL, isn’t much use because it was developed for hand-coding, before computers, and isn’t discriminating enough.
The sample word table has the metaphone stored with each word. This means that all you need to do is to find the metaphone for the word and search the metaphone column.
Lets return to our extreme example from the introduction.
|
1 2 |
SELECT COALESCE(words.CanonicalVersion,words.word) AS candidate FROM words WHERE metaphone =dbo.metaphone('sossyjez') |
![]()
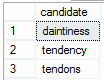
We aren’t always that lucky in getting just one candidate that matches. If we” by the same technique:
|
1 2 |
SELECT COALESCE(words.CanonicalVersion,words.word) AS candidate FROM words WHERE metaphone =dbo.metaphone('tendancy') |
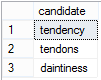
We can get the most likely ones listed first in the candidate list by ordering the candidates by their edit difference:
|
1 2 3 4 |
SELECT COALESCE(words.CanonicalVersion,words.word) AS candidate FROM words WHERE metaphone =dbo.metaphone('tendancy') ORDER by COALESCE(dbo.DamLev(word,'tendancy',3),4) --order by their ascending edit difference --but only up to three edit differences |
In a simple test run, for 30 common misspellings, a fifth of the misspellings in total, the metaphone comparison showed a different metaphone for the common misspelling than for the correct spelling. Only three of these were misspellings that the edit-difference approach also failed to resolve correctly, but it means that it was quite likely to suggest the wrong word, if used by itself. In other words, the metaphone approach would be no good on its for resolving those common misspellings, but is still a good fall back for when the edit-difference approach fails to deliver.
The general problem with the metaphone approach comes from the language itself in that a great number of common words sound alike if one eliminates the ‘syllabic peak or nucleus’, by making vowels all alike. As a Metaphone tries to represent the sounds, in some cases it is very discriminating, too discriminating in fact, and in other cases it would come up with fifty matches.
However, if you get too many, then you can fall back on a function that calculates the edit distance, preferably a fast Damerau-Levenshtein such as Steve Hatchett’s version here Optimizing the Damerau-Levenshtein Algorithm in TSQL . You can then order the candidates by their edit difference to get the most likely candidates. The best approach is to limit the search to strings that are two edit differences away; anything further is pretty pointless for finding similar strings because at three edit-differences away, they just aren’t similar! I believe that some applications attempt to find edit differences between the metaphones themselves but I think that is probably taking things too far.
Hard-coded Common Misspellings, Dialect Words and Aliases
Sometimes, a common misspelling is more than a single edit away from the intended search term, and won’t be picked up by either our “edit difference” or sound-alike algorithms. In such cases, you can treat it as a hard-coded alias. We also need a special way of catching dialect words and other synonyms that can’t be caught any other way.
Let’s illustrate this simply.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
-- We create a temporary table that holds a table that holds the English words for the -- numbers one to ten CREATE TABLE #Numberwords (word VARCHAR(10) PRIMARY KEY, CanonicalVersion VARCHAR(10) NULL, ) -- We put the numbers one to ten in, leaving the canonicalversion field with a NULL -- bwecause these are, if I've typed them right, the canonical version INSERT INTO #Numberwords (word) VALUES ('one'),('two'),('three'),('four'),('five'),('six'),('seven'), ('eight'),('nine'),('ten') --now we put in some of the common misspellings, along with the proper 'canonical' spellings INSERT INTO #Numberwords (word,CanonicalVersion) VALUES('wun','one'),('too','two'),('free','three'),('fower','four'),('thive','five'), ('sicks','six'),('sevvern','seven'),('ayt','eight'),('nign','nine'),('tenn','ten') --and a few synonyms, just to show that we can cope with both INSERT INTO #Numberwords (word,CanonicalVersion) VALUES('1','one'),('2','two'),('3','three'),('4','four'),('5','five'), ('6','six'),('7','seven'),('8','eight'),('9','nine'),('10','ten') --and now we make sure that it always returns the canonical version SELECT COALESCE(canonicalversion,word) FROM #Numberwords WHERE word LIKE 'fower' --returns 'four' SELECT COALESCE(canonicalversion,word) FROM #Numberwords WHERE word LIKE '5' --returns 'five' --and we can still so fuzzy searches of the canonical versions. SELECT word FROM #numberwords WHERE CanonicalVersion IS NULL AND word LIKE 'th%' |
You will see that this technique doesn’t allow an alias or misspelling that is a real ‘canonical’ word. This means that word confusions can only be spotted in context, and also you’re not going to cope with the difference between ‘pants’ and ‘trousers’ this way.
It also doesn’t allow you to misspell an alias. ‘Crawdads’ need to be spelled right if you are asking for a ‘crayfish’. However, in this case, you can allow aliases in the initial edit-difference approach. It is a matter of fine-tuning for your application.
Putting it all together
By now, if you’ve been following my argument, the best tactic is probably going to be a composite one. The first stage is to see if a word is an alias or a known misspelling. If not, then has it an edit-distance of one to any canonical words in your table? If not then does it share a metaphone with any canonical words in your table? If yes, and there are too many, sort them in ascending edit difference and take the top few. Otherwise, just return them. If no, then it is time to get something at least by getting a limited number of words with an edit distance of two, using Steve Hatchett’s version of the Damerau-Levenshtein Algorithm, specifying that it abandons its work on a particular word once it realises that it is more than two edit distances away.
The general principles are:
- Use fast table searches where the word is the clustered primary key wherever possible.
- Where you are forced to use a slow algorithm, reduce your candidate set as much as possible beforehand using SQL’s built-in text searching.
- Make sure that your search feature can learn, or rather be taught, from the search terms that cause difficulty. This means logging all searches and their success, and use this data to maintain the aliases.
Here’s the complete “fuzzy search” algorithm:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
IF OBJECT_ID (N'dbo.FuzzySearchOf') IS NOT NULL DROP FUNCTION dbo.FuzzySearchOf GO CREATE FUNCTION dbo.FuzzySearchOf(@Searchterm VARCHAR(40)) /** summary: > Returns all candidate words even if the input word is misspelt Author: Phil Factor Revision: 1.0 date: 16/02/2017 example: Select * from dbo.FuzzySearchOf('sossyjez') Select * from dbo.FuzzySearchOf('acheeve') Select * from dbo.FuzzySearchOf('deevyate')--does a returns: > a table containing words Dependency: Words: A table of common words DamLev http://blog.softwx.net/2015/01/optimizing-damerau-levenshtein_19.html dbo.OneEditDifferenceTo(@word) dbo.metaphone(@searchterm) **/ RETURNS @candidates TABLE(Candidate VARCHAR(40)) AS -- body of the function BEGIN DECLARE @Rowcount INT; /* The first stage is to see if a word is an alias or a known misspelling.*/ INSERT INTO @candidates (Candidate) SELECT COALESCE(words.CanonicalVersion, words.word) FROM dbo.words WHERE words.word = @Searchterm; -- If not a known word or an alias, then has it an edit-distance of one to any canonical words -- IN the 'Words' table IF @@RowCount = 0 BEGIN INSERT INTO @candidates (Candidate) SELECT OneEditDifferenceTo.Candidate FROM dbo.OneEditDifferenceTo(@Searchterm); IF @@RowCount = 0 BEGIN --If not then does it share a metaphone with any words in your table? INSERT INTO @candidates (Candidate) SELECT COALESCE(words.CanonicalVersion, words.word) AS candidate FROM dbo.words WHERE words.Metaphone = dbo.Metaphone(@Searchterm); SELECT @Rowcount = @@RowCount; IF @Rowcount > 5 --If yes, and there are too many, then get what there are and BEGIN --take the top few in ascending edit difference. DELETE FROM @candidates; INSERT INTO @candidates (Candidate) SELECT TOP 5 COALESCE(words.CanonicalVersion, words.word) AS candidate FROM dbo.words WHERE words.Metaphone = dbo.Metaphone(@Searchterm) ORDER BY COALESCE(dbo.DamLev(words.word, @Searchterm, 3), 4); --just do three levels END; IF @Rowcount = 0 BEGIN /* Get a limited number of words with an edit distance of two, using Steve Hatchett’s version of the Damerau-Levenshtein Algorithm, specifying that it abandons its work on a particular word once it realises that it is more than two edit distances away*/ INSERT INTO @candidates (Candidate) SELECT TOP 5 words.word FROM dbo.words WHERE words.CanonicalVersion IS NULL AND word LIKE LEFT(@Searchterm,1)+'%' AND COALESCE(dbo.DamLev(words.word, @Searchterm, 2), 3) < 3; END; END; END; RETURN; END; GO |
We can now test this with this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
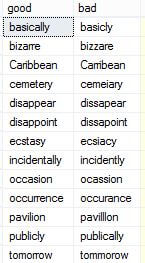
DECLARE @timer DateTime2 SELECT @timer=GETDATE() SELECT good, bad, candidate FROM (VALUES ('across','accross'),('aggressive','agressive'),('aggression','agression'),('apparently','apparantly'), ('appearance','appearence'),('argument','arguement'),('assassination','assasination'), ('absence','absense'),('absence','absance'),('absence','absense'),('acceptable','acceptible'), ('accidentally','accidentaly'),('accommodate','acommodate'),('achieve','acheive'),('acknowledge','acknowlege'), ('acknowledge','aknowledge'),('acquaintance','acquaintence'),('acquaintance','aquaintance'), ('acquire','aquire'),('acquire','adquire'),('acquit','aquit'),('acreage','acrage'),('acreage','acerage'), ('address','adress'),('adultery','adultary'),('advisable','adviseable'),('advisable','advizable'), ('aggression','agression'),('aggressive','agressive'),('allegiance','allegaince'),('allegiance','allegience'), ('allegiance','alegiance'),('almost','allmost'),('amateur','amatuer'),('amateur','amature'), ('annually','anually'),('annually','annualy'),('apparent','apparant'),('apparent','aparent'), ('arctic','artic'),('argument','arguement'),('atheist','athiest'),('awful','awfull'),('awful','aweful'), ('basically','basicly'),('beginning','begining'),('believe','beleive'),('believe','belive'), ('bizarre','bizzare'),('business','buisness'),('calendar','calender'),('Caribbean','Carribean'), ('cemetery','cemeiary'),('chauffeur','chauffer'),('colleague','collegue'),('coming','comming'), ('committee','commitee'),('completely','completly'),('conscious','concious'),('curiosity','curiousity'), ('definitely','definately'),('dilemma','dilemna'),('disappear','dissapear'),('disappoint','dissapoint'), ('ecstasy','ecsiacy'),('embarrass','embarass'),('environment','enviroment'),('existence','existance'), ('familiar','familar'),('finally','finaly'),('fluorescent','florescent'), ('foreign','foriegn'),('foreseeable','forseeable'),('forty','fourty'),('forward','foward'), ('friend','freind'),('further','futher'),('gist','jist'),('glamorous','glamourous'),('government','goverment'), ('guard','gaurd'),('happened','happend'),('harass','harrass'),('harassment','harrassment'),('honorary','honourary'), ('humorous','humourous'),('idiosyncrasy','idiosyncracy'),('immediately','immediatly'), ('incidentally','incidently'),('independent','independant'),('interrupt','interupt'), ('irresistible','irresistable'),('knowledge','knowlege'),('liaise','liase'),('liaison','liason'),('lollipop','lollypop'), ('millennium','millenium'),('millennia','millenia'),('Neanderthal','Neandertal'),('necessary','neccessary'), ('noticeable','noticable'),('occasion','ocassion'),('occasion','occassion'),('occurred','occured'), ('occurring','occuring'),('occurrence','occurance'),('occurrence','occurence'),('pavilion','pavilllon'), ('persistent','persistant'),('pharaoh','pharoah'),('piece','peice'),('politician','politican'), ('Portuguese','Portugese'),('possession','Possession'),('preferred','prefered'),('preferring','prefering'), ('propaganda','propoganda'),('publicly','publically'),('really','realy'),('receive','recieve'), ('referred','refered'),('referring','refering'),('religious','religous'),('remember','rember'), ('remember','remeber'),('resistance','resistence'),('sense','sence'),('separate','seperate'), ('siege','seige'),('successful','succesful'),('supersede','supercede'),('surprise','suprise'), ('tattoo','tatoo'),('tendency','tendancy'),('therefore','therefor'),('threshold','threshhold'), ('tomorrow','tommorow'),('tomorrow','tommorrow'),('tongue', 'tounge'),('truly','truely'), ('unforeseen','unforseen'),('unfortunately','unfortunatly'),('until','untill'),('weird','wierd'), ('wherever','whereever'),('which','wich') )f(good,bad) OUTER APPLY dbo.FuzzySearchOf(bad) |
Conclusions
Many times in the past, I’ve had arguments with members of the development teams who, when we are discussing fuzzy searches, draw themselves up to their full height, look dignified, and say that a relational database is no place to be doing fuzzy searches or spell-checking. It should, they say, be done within the application layer. This is nonsense, and we can prove it with a stopwatch.
We are dealing with data. Relational databases do this well, but it just has to be done right. This implies searching on well-indexed fields such as the primary key, and not being ashamed of having quite large working tables. It means dealing with the majority of cases as rapidly as possible. It implies learning from failures to find a match. It means, most of all, a re-think from a procedural strategy.


